
プラグインやテーマの機能で気軽にSEO対策ができるようになりましたが、中には「このページはどうすればいいんだろう…?」と困るケースもあります。
例えば、WordPressプラグインが自動生成したページをnoindexしたい場合など。
カスタム投稿タイプの機能で生成されているなら設定項目を追加できるのでいいんですが、それ以外のページに関してはURL入力欄を用意してnoindex処理をするなどの手間がかかるからです。
そこで活用したいのが「robots.txt」です。
WordPress以外のサイトでも使えますし、検索結果に表示されると都合が悪い…といったSEO対策以外の目的でも重宝するので、使い方を知っておいて損はありませんよ。
robots.txtとは?
まず、robotx.txtについてですが、これはクローラー(検索エンジンのロボット)に指示・命令を伝えるファイルです。
- このページはクロールしないでね
- このフォルダ(ディレクトリ)はクロールしないでね、でもその中のページAだけクロールしていいよ
といった内容をファイルに記述することで、クローラーの行動を制限(最適化)し、検索結果に影響を与えることが可能です。
robots.txtとnoindexの関係
なぜ、robots.txtが検索結果に影響を与えるのかと言うと、検索結果に表示される主な手段がクローラーにクロールされることだからです。
Google によるページのクロールをブロックすると、そのページのランキングが低下したり、時間が経つにつれて表示されなくなったりする可能性があります。また、検索結果の下に表示される、ユーザーに提示する詳細テキストの量が少なくなる可能性もあります。これは、ページのコンテンツがないと、検索エンジンで処理する情報が大幅に減るためです。
robots.txt で disallow ディレクティブを使用して Google によるページのクロールをブロックした場合、ページは検索結果に表示されなくなりますか?
つまり、検索結果に表示して欲しくない場合はrobots.txtにクロールを拒否する指示・命令を記述すればいいわけですね。
実際には100%クローラーをコントロールできるわけではなく、クロールを拒否したのに検索結果に表示されることもありますが、これがrobots.txtを使ってページをnoindexにする方法であり、仕組みです。
クロールされないのに検索結果に表示される主な要因は他のページからのリンクです。
ただし、robots.txt で Disallow を使用しても、ページが確実に検索結果に表示されなくなるとは限りません。外部からのリンクなどの情報に基づいて、引き続き、関連性のあるページと判断されることがあります。
robots.txt で disallow ディレクティブを使用して Google によるページのクロールをブロックした場合、ページは検索結果に表示されなくなりますか?
また、noindexのメタタグと同様の効果がある「Noindex」というディレクティブもあり、本来はDisallowではなくこちらを使うべきなんですが、完全にサポートされているディレクティブではないようなので、クロール拒否によるnoindexを期待するのが現状の「正攻法」になっています。
参考robots.txtのNoindex(Disallowではない!)を使ったPageRankスカルプティング
【追記】Noindexディレクティブは正式に「廃止」になるそうです。
robots.txtの使い方
では、robots.txtの使い方をご紹介します。
今回は例として、bbpressのユーザーページをnoindexにする手順です。
まず、サーチコンソールの「robots.txtテスター」をクリック。
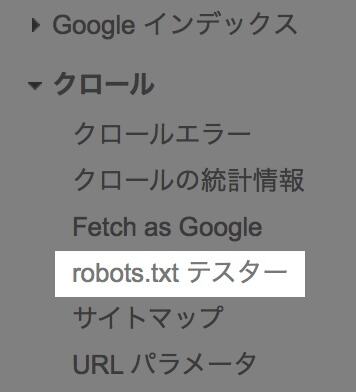
ここでファイルを直接編集します。
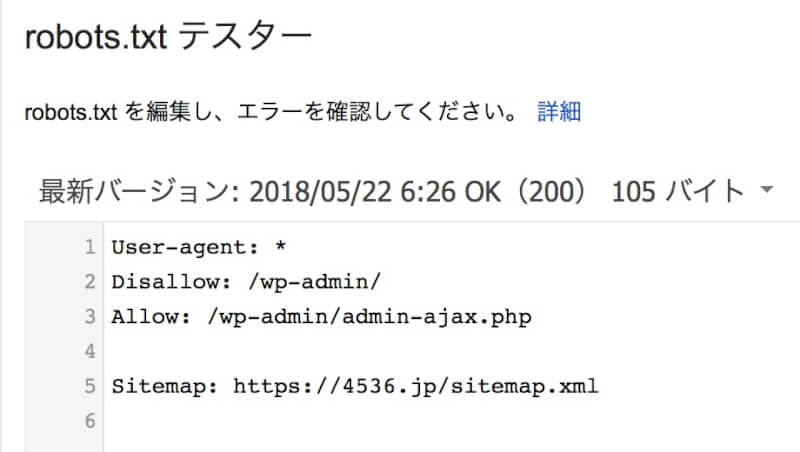
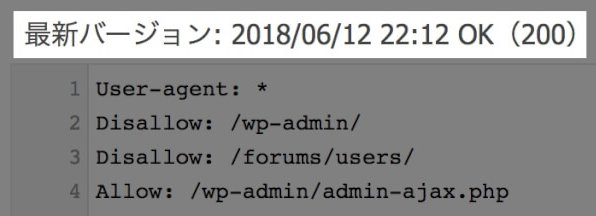
クロールを拒否するので、行の先頭に「Disallow」と記述。
その後に、セミコロン、半角スペースを入力し、クロールを拒否したいパス(URL)を記述します。
こちらの画像だと、forumsディレクトリの下のusersディレクトリへのクロールをすべて拒否していることになります。
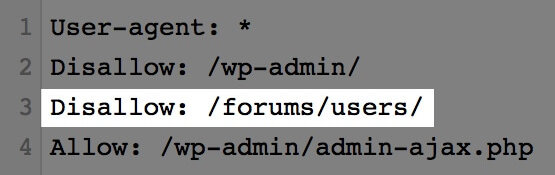
正しく記述できていれば、URLを入力して「テスト」をクリックすると「ブロック済み」になります。

動作を確認したら、右下の「送信」をクリック。

次の画面で「ダウンロード」をクリック。

ダウンロードしたテキストファイルはドメインのルートフォルダ直下に置きます。
WordPressの場合はpublic_htmlの下(wp-adminなどのファイルがある場所)になります。
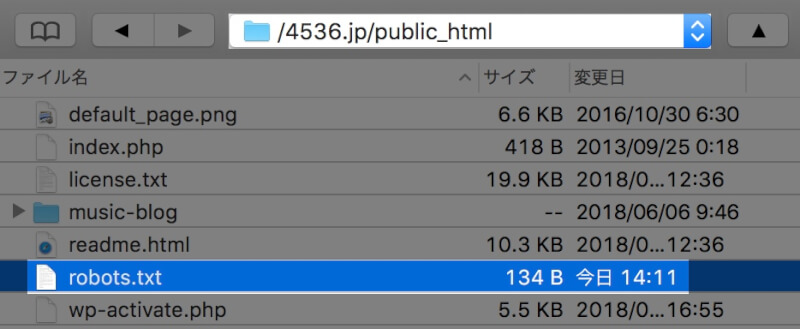
ファイルのアップロードが完了したら、サーチコンソールに戻り「送信」をクリック。

その後ページを読み込み、バージョンの日付が更新されていればOKです。
robots.txtのディレクティブの種類
robots.txtには主に以下の3つの「ディレクティブ」があります。
(ディレクティブとは「命令」のことです)
- Allow(クロールを許可)
- Disallow(クロールを拒否)
- sitemap(サイトマップの場所を示す)
基本的には今回ご紹介した「Disallow」を使うことになると思いますが、Aのディレクトリ(フォルダ)は拒否するけど、Aのディレクトリの中にあるページBだけ許可のような場合に「Allow」を使います。
sitemapのディレクティブはWordPressの場合プラグインが変わりにやってくれる機能があるので特に記述する必要はありません。CMSなどを使わずにサイトを構築している場合だけ記述します。

ディレクティブについてもっと詳しく知りたい方はこちらのページが参考になると思います。
Disallowとrobotsメタタグとの違い
Disallowとrobotsメタタグの何が違うのか疑問に思うかもしれません。
robotsメタタグとは以下のようなタグです。
<meta name="robots" content="noindex,follow">まず、両者の違いについてですが、robots.txtはクローラーを制御するもので、robotsメタタグはインデックスするかどうかを制御するもの。
つまり、前者はクロールを拒否することで「クロールして欲しくないってことはindexして欲しくないってことだよ〜」と間接的に伝え、後者はクロールしてきたクローラーに「このページはnoindexしてね」と直接伝えます。
また、両者の性質を考えるとわかると思いますが、併用するべきではありません。
robots.txtでクロールを拒否してしまうとnoindexのrobotsメタタグがあるかどうかクローラーがわからないからです。
併用すること自体は可能ですが、先述の通り、確実にnoindexさせるならrobotsメタタグを使うべきなので、どちらの方法も使えるならrobotsメタタグを使うのが良いでしょう。
参考noindex を使用して検索インデックス登録をブロックする
robots.txtの利用シーン
今回のように、ページ単位でrobotsメタタグが使えないケースはもちろんのこと、ディレクトリ単位で制御できるのがrobots.txtの便利なところ。
掲示板プラグインで第三者が生成するページをすべてnoindexに…なんてことも数分で設定できます。
ページ単位で設定している場合はページが生成されるたびにnoindex処理をしないといけないので、その手間を考えると非常に便利ではないでしょうか。
